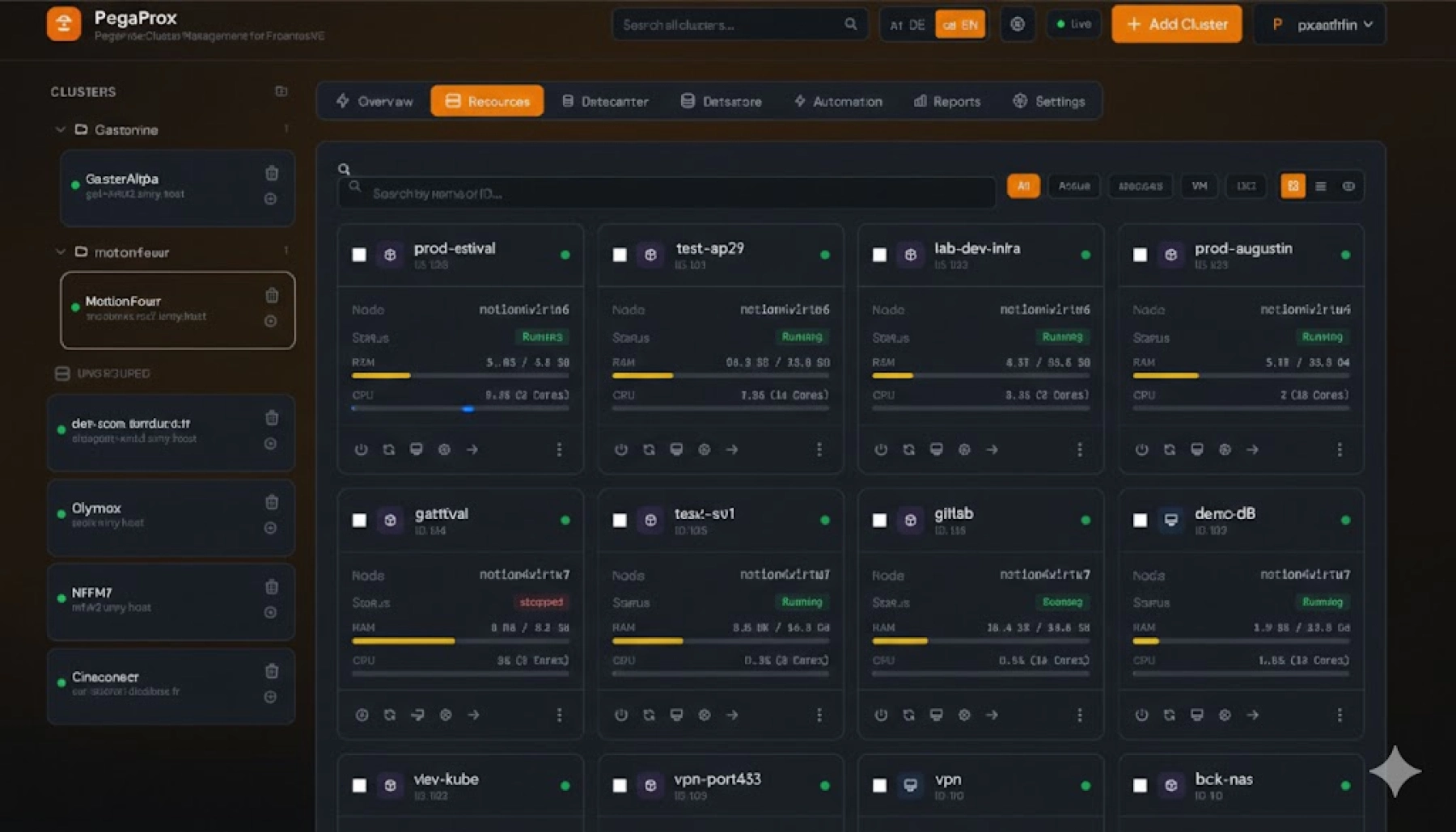
vLLM vs Ollama : Comparons les outils de déploiement de vos modèles d'IA
Dans le paysage en constante évolution de l'IA, des solutions d'inférence efficaces sont cruciales pour déployer des grands modèles de langage (LLMs). Deux outils éminents dans ce domaine sont vLLM et Ollama, chacun répondant à des besoins et des cas d'utilisation différents.
Plongeons dans une comparaison détaillée pour vous aider à choisir l'outil adapté à vos applications d'IA.
Introduction à VLLM et Ollama
VLLM (Very Large Language Model) : vLLM est conçu pour améliorer l'efficacité des LLMs, en particulier dans des scénarios à haut débit.
Développé par l'Université de Californie à Berkeley, vLLM excelle dans la gestion de multiples requêtes simultanément, le rendant idéal pour des applications d'IA à grande échelle comme les chatbots et les moteurs de recherche.
Ollama : Ollama est plus convivial et simplifie le déploiement et la gestion des LLMs sur des machines locales.
Il privilégie la facilité d'utilisation et la flexibilité, le rendant accessible aux développeurs et aux passionnés d'IA qui souhaitent expérimenter avec des modèles d'IA sans configurations complexes.
Performance et évolutivité
VLLM :
- Haut débit : vLLM est optimisé pour une génération rapide de tokens et une gestion efficace de la mémoire. Il charge le modèle en Vram ec qui le rend réactif à vos demandes.
Il utilise des techniques innovantes comme PagedAttention pour gérer de grandes fenêtres de contexte sans consommation excessive de mémoire GPU. - Concurrence : vLLM peut gérer plusieurs requêtes efficacement, maintenant la vitesse même avec une forte concurrence. Il est conçu pour maximiser l'utilisation du GPU grâce à l'empilement continu et à l'allocation dynamique de la mémoire.
- Cas d'utilisation : Idéal pour des applications de niveau entreprise nécessitant des performances élevées et une évolutivité, telles que les bots de service client et les moteurs de recherche alimentés par l'IA.
Ollama :
- Vitesse limité : Ollama offre une vitesse d'inférence décente mais est limitée par les capacités matérielles locales. Il est adapté à l'exécution de modèles plus petits sur des ordinateurs personnels et des appareils périphériques.
- Concurrence : Bien qu'Ollama puisse gérer plusieurs requêtes, ses performances peuvent se dégrader à mesure que le nombre de requêtes simultanées augmente.
Il est mieux adapté à une utilisation limité et locale ou le temps de réponse posera moins de problème. - Cas d'utilisation : Parfait pour les développeurs qui ont besoin d'une solution simple et conviviale pour une gestion locale ou le prototypage.
Typiquement lorsque vous travaillez seul sur une IA privée ou que vous souhaitez tester la pertinance sans un déploiement conséquent.
Facilité d'utilisation et déploiement
VLLM :
- Complexité de configuration : vLLM nécessite une configuration plus complexe, en particulier pour les petits déploiements. Il est principalement optimisé pour les GPU NVIDIA et est sensible aux drivers, version d'OS et autre support de vos équipements.
Il ne se laisse pas manipuler facilement, sensible et délicat, il faudra en prendre soin surtout lors de vos mises à jour. - Personnalisation : Offre des options de personnalisation approfondies pour les développeurs qui doivent ajuster des modèles et optimiser les performances pour des cas d'utilisation spécifiques.
Ollama :
- Convivialité : Ollama est conçu pour la simplicité. Il fournit une CLI et une API simples pour déployer et gérer des modèles, le rendant accessible aux utilisateurs de tous niveaux techniques.
Un simple script bash est à disposition pour le déployer sur un grand nombre de machine linux. - Flexibilité : Prend en charge l'utilisation du GPU et/ou du CPU, offrant une compatibilité matérielle plus large.
C'est un excellent choix pour les environnements avec des configurations matérielles diverses et sans doute.
Gestion de la mémoire et efficacité
vLLM :
- PagedAttention : Le mécanisme PagedAttention de vLLM optimise l'utilisation de la mémoire et permet une allocation dynamique de celle-ci, le rendant très efficace pour l'utilisation du GPU.
- Pré-allocation de mémoire : vLLM pré-alloue la mémoire GPU l'intégralité du LLM de votre choix, assurant une flexibilité et une vitesse maximale mais nécessitant des ressources GPU importantes.
Par exemple, le Mistral small 3.1 doit disposer d'une carte GPU avec 80Go de Vram pour être déployé correctement.
Ollama :
- Utilisation flexible de la mémoire : Ollama offre une gestion flexible de la mémoire, le rendant adapté aux environnements à ressources limitées.
Cependant, il peut ne pas être aussi optimisé que vLLM pour les configurations GPU haut de gamme. - Streaming de tokens : Ollama fournit un streaming de tokens optimisé pour des réponses rapides, bénéficiant aux tâches d'inférence en temps réel comme les chatbots.
Intégration et les outils
L'intégration de VLLM et Ollama avec des interfaces comme OpenWebUI et LangFlow permet d'exploiter pleinement les capacités des grands modèles de langage (LLM) dans des environnements conviviaux et accessibles.
OpenWebUI est une interface utilisateur web autohébergée, extensible et riche en fonctionnalités, conçue pour fonctionner entièrement hors ligne. Elle prend en charge divers moteurs d'exécution de LLM, y compris Ollama et les API compatibles openAI, offrant ainsi une plateforme flexible pour interagir avec les modèles d'IA.
En intégrant Ollama avec OpenWebUI, les utilisateurs peuvent facilement déployer et gérer des modèles d'IA sur leurs propres serveurs, tout en bénéficiant d'une interface intuitive pour tester et affiner les modèles sans dépendre de services cloud.
vLLM devra être lancé en compatibilité d'API openai avec un token d'accès et un port spécifique.
LangFlow, quant à lui, est un framework permettant de développer des applications alimentées par des LLM. Il facilite la création de workflows complexes en combinant les capacités des LLM avec d'autres outils et services. L'intégration de vLLM ou Ollama avec LangFlow permet aux développeurs de créer des applications d'IA personnalisées qui peuvent automatiser des tâches, générer du contenu ou interagir dynamiquement avec les utilisateurs.
Cette approche modulaire permet une personnalisation poussée et une adaptation rapide aux besoins spécifiques des projets, tout en tirant parti des performances optimisées des frameworks d'inférence comme vLLM.
Ces intégrations permettent d'exploiter pleinement les technologies d'IA les rendant simple et accessible au plus grand nombre.
L'IA privée devient le nouveau collaborateur de votre société. Rapide et disponible, elle améliore votre productivité ainsi que celle de l'ensemble de vos services.
Que choisir entre vLLM et Ollama ?
Le choix entre vLLM et Ollama dépend de vos besoins spécifiques et de vos cas d'utilisation. vLLM est la solution de référence pour les applications d'IA à grande échelle nécessitant une inférence et une évolutivité efficaces.
D'autre part, Ollama est idéal pour les développeurs et les passionnés d'IA qui ont besoin d'un cadre convivial et flexible pour la gestion locale et le prototypage.
Nous vous conseillerons donc l'utilisation de vLLM pour vos IA privées en production, celles qui doivent être réactive et disponible pour le plus grand nombre.
Dans le cas d'une utilisation plus maitriser, en développement ou pour des tests, Ollama est adapté et vous permettra l'utilisation de plusieurs LLM en parallèle.
Vous avez des questions ou besoin d'une solution LLM privée ? Contactez-nous dès maintenant.