Sommaire
- Déploiement d'une IA privée avec vLLM sur Ubuntu
- Prérequis pour l'installation d'une IA privée sur Ubuntu
- Étape 1 : Installation des dépendances
- Étape 2 : Installation des drivers Nvidia
- Étape 3 : Installation de huggingface-cli
- Étape 4 : Installation de vLLM
- Étape 5 : Configuration de vLLM
- Étape 6 : Utilisation du modèle
- Étape 7 : Script de lancement au démarrage
- En résumé
Dans un monde où l'intelligence artificielle devient de plus en plus omniprésente, le déploiement de modèles d'IA privés et performants est une nécessité pour de nombreuses entreprises et développeurs. Cet article vous guide pas à pas dans le déploiement d'un modèle d'IA privé en utilisant vLLM sur un système Ubuntu.
Déploiement d'une IA privée avec vLLM sur Ubuntu
Dans cet article, nous allons vous guider pour le déploiement d'un modèle d'IA privée en utilisant vLLM sur un système Linux.
Pour des raisons pratiques et de compatibilité de driver, notre exemple repose sur les éléments suivants:
- Ubuntu 22.04
- Installation de base effectuée
- Carte graphique Nvidia A100
- Le modèle MistralAI/Mistral-Small-3.1-24B-Instruct-2503 car il est partinent dans une utilisation large.
Prérequis pour l'installation d'une IA privée sur Ubuntu
Avant de commencer, assurez-vous d'avoir les éléments suivants :
- Disposer d'un environnement avec une carte graphique d'au moins 70Go de Vram
- Un système Ubuntu (de préférence la dernière version LTS)
- Un accès à un terminal avec des privilèges sudo. (nous sommes root ici mais préférez un utilisateur sudo
- Un compte Hugging Face avec un token valide
Étape 1 : Installation des dépendances
Ouvrez un terminal et mettez à jour votre système :
sudo apt update
sudo apt upgrade -y
Installez les dépendances nécessaires :
sudo apt -y install python3 python3-pip git apt-transport-https ca-certificates curl software-properties-common gnupg-agent
Étape 2 : Installation des drivers Nvidia
La compatibilité entre les drivers Nvidia et les systèmes Linux n'est pas toujours optimale A date, il semble que le plus adapté soit nvidia-driver-570-server.
Installez le repo et le driver nvidia avec en bonus la possitilité de passer sur docker:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt install nvidia-driver-570-serversudo apt -y install nvtopnvtop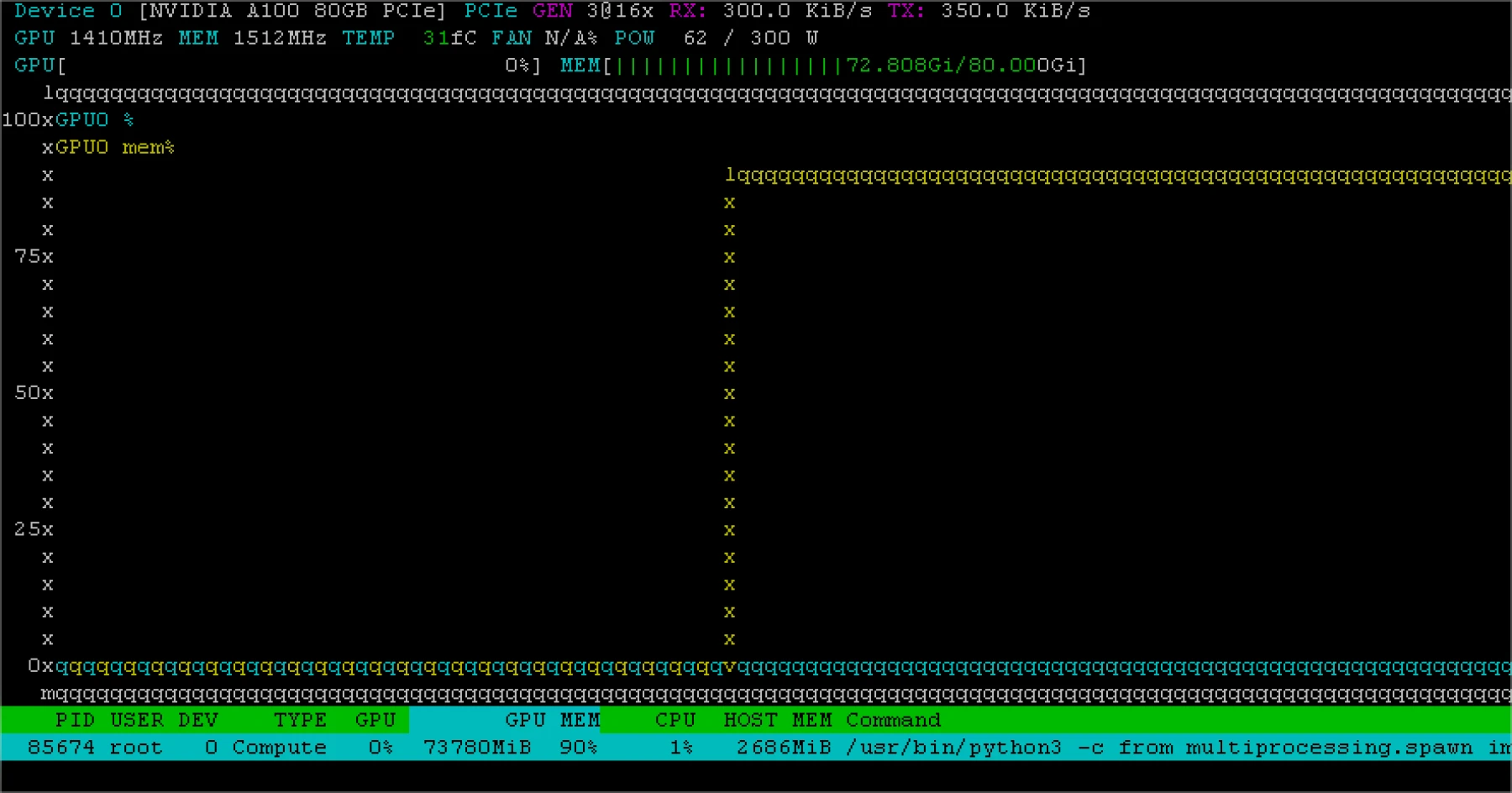
Étape 3 : Installation de huggingface-cli
Hugginface est codé en python, nous en avons besoin pour aller chercher le modèle de notre choix
Installez huggingface-cli en utilisant pip :
apt install python3.11-venv
pip install -U "huggingface_hub[cli]"
pip install --upgrade mistral_commonhuggingface-cli login
Étape 4 : Installation de vLLM
Installez simplement vLLM en utilisant pip :
pip install vllmpip install --upgrade mistral_common
Étape 5 : Configuration de vLLM
Maintenant que tous les éléments sont installés pour lancer vllm avec votre modèle, ya plus qu'a se lancer :
vllm serve mistralai/Mistral-Small-3.1-24B-Instruct-2503 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --api-key token-PRcoct3gqpcQt9870 --port 8000 vllm serve: Pas besoin d'expliquer mais on indique que vous utilisez vLLM pour servir un modèle de langage.mistralai/Mistral-Small-3.1-24B-Instruct-2503: C'est le nom du modèle que vous souhaitez servir. Dans ce cas, il s'agit du modèle Mistral-Small-3.1-24B-Instruct-2503 de MistralAI définit par Hugginface--tokenizer_mode mistral: Ce paramètre spécifie le mode du tokenizer à utiliser. Ici, il est configuré pour utiliser le mode "mistral", ce qui signifie qu'il utilisera le tokenizer spécifique à Mistral.
Chaque grand modèle possède son tokenizer--config_format mistral: Ce paramètre indique le format de configuration à utiliser pour le modèle. Dans ce cas, il est biensur configuré pour utiliser le format "mistral".--load_format mistral: Ce paramètre spécifie le format de chargement du modèle.--tool-call-parser mistral: Ce paramètre indique le parser à utiliser pour les appels d'outils.--enable-auto-tool-choice: Lorsque cette option est activée, le modèle est capable de sélectionner automatiquement les outils ou les fonctionnalités les plus appropriés pour répondre à une requête donnée. Cela signifie que le modèle peut décider quel outil utiliser en fonction du contexte de la question ou de la tâche à accomplir.
Contexte et Pertinence : Par exemple, si une requête nécessite une recherche d'informations, le modèle pourrait automatiquement choisir un outil de recherche. Si la requête nécessite une analyse de données, le modèle choisira un outil d'analyse.Amélioration de l'Efficacité : Cette fonctionnalité vise à améliorer l'efficacité et la pertinence des réponses en utilisant les outils les plus adaptés pour chaque situation spécifique.
--api-key token-PRcoct3gqpcQt9870: La clé API sert pour l'authentification des appels surtout externes. Ici, la clé API est "token-PRcoct3gqpcQt9870".
Changez là pour votre cas précis 😇--port 8000: Ici on indique le port sur lequel le serveur vLLM écoutera les requêtes.
Par défaut, c'est le port 8000 qui est choisit
Étape 6 : Utilisation du modèle
Notre Mistral Small tourne, nvtop nous indique qu'il est chargé en Vram (cf mon screenhost plus haut)
Il ne reste qu'à l'interroger pour savoir s'il répond bien.
| curl -X POST "http://localhost:8000/v1/chat/completions" \ :( -H "Content-Type: application/json" \ -H "Authorization: Bearer token-PRcoct3gqpcQt9870" \--data '{ "model": "mistralai/Mistral-Small-3.1-24B-Instruct-2503", "messages": [ { "role": "user", "content": "quel est la valeur exact de 3 fois pi " } ] }' |
Vous devriez avoir un retour :
| {"id":"chatcmpl-93aa405fac724107a43f47139aea802f","object":"chat.completion","created":1748364116,"model":"mistralai/Mistral-Small-3.1-24B-Instruct-2503","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"La valeur exacte de \\(3 \\times \\pi\\) est \\(3\\pi\\).\n\nCela signifie que \\(3 \\times \\pi\\) est une expression mathématique qui combine le nombre 3 avec la constante \\(\\pi\\) (pi), qui est approximativement égale à 3.14159. Cependant, la valeur exacte reste \\(3\\pi\\).\n\nSi tu souhaites une approximation numérique, tu peux utiliser la valeur approximate de \\(\\pi\\) (environ 3.14159) pour obtenir :\n\n\\[ 3 \\times 3.14159 \\approx 9.42477 \\]\n\nCela donne une approximation, mais la valeur exacte est toujours \\(3\\pi\\).","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":14,"total_tokens":162,"completion_tokens":148,"prompt_tokens_details":null},"prompt_logprobs":null}# |

Étape 7 : Script de lancement au démarrage
Il ne reste qu'à créer le script de démarrage et le service systemd.
vi /usr/local/bin/run_vllm.sh
|
#!/bin/bash MODEL="mistralai/Mistral-Small-3.1-24B-Instruct-2503" vllm serve $MODEL --tokenizer_mode $TOKENIZER_MODE --config_format $CONFIG_FORMAT --load_format $LOAD_FORMAT --tool_call_parser $TOOL_CALL_PARSER $ENABLE_AUTO_TOOL_CHOICE --api-key $API_KEY --port $PORT |
chmod +x /usr/local/bin/run_vllm.sh
vi /etc/systemd/system/vllm.service
|
[Unit] [Service] [Install] |
| systemctl daemon-reload systemctl enable vllm.service systemctl start vllm.service |
Votre service vLLM est maintenant fonctionnel et tourne sur le port 8000 !

En résumé
Vous savez maintenant déployer une IA privée grâce à vLLM. Il semble qu'actuellement c'est l'outil le plus performant pour travailler sur votre IA au quotidient avec un grand nombre d'utilisateurs.
Bien que l'investissement de départ soit important les avantages de cette utilisation sont nombreux.
- Réactivité du modèle car directement chargé en Vram
- Coût faible avec un grand nombre d'utilisateur
- Maitrise de vos données sensibles, n'ayant plus peur de partager des documents confidentiels avec l'IA
- Possibilité de déployer un grand nombre de modèles différents, tant que la partie graphique est suffisante
- Ne plus dépendre d'un GAFAM.
Vous souhaitez mettre en place votre propre IA privée ou avez besoin d’un accompagnement technique pour vos projets ? Contactez-moi dès aujourd’hui.
Je vous propose des solutions sur mesure, performantes et sécurisées, adaptées à vos besoins professionnels. Ensemble, donnons vie à votre infrastructure IA de demain.