Après avoir présenté dans une série d’articles la mise en place d’un cluster Proxmox VE réparti sur trois zones de disponibilité OVHcloud, je suis allé plus loin côté stockage distribué avec Ceph.
Cette annexe revient sur un aspect souvent négligé mais pourtant essentiel : la CRUSH map. Sans une hiérarchie claire, vos réplicas peuvent se retrouver sur le même site, ruinant la tolérance de panne que vous croyiez acquise. Voici comment structurer votre CRUSH map pour garantir une réplique par site et une vraie HA multi-AZ.
Architecture de référence
| Site | Zone | Nœud | Disques |
|---|---|---|---|
| Paris-A | AZ 1 | Serveur 1 | 2 × NVMe |
| Paris-B | AZ 2 | Serveur 2 | 2 × NVMe |
| Paris-C | AZ 3 | Serveur 3 | 2 × NVMe |
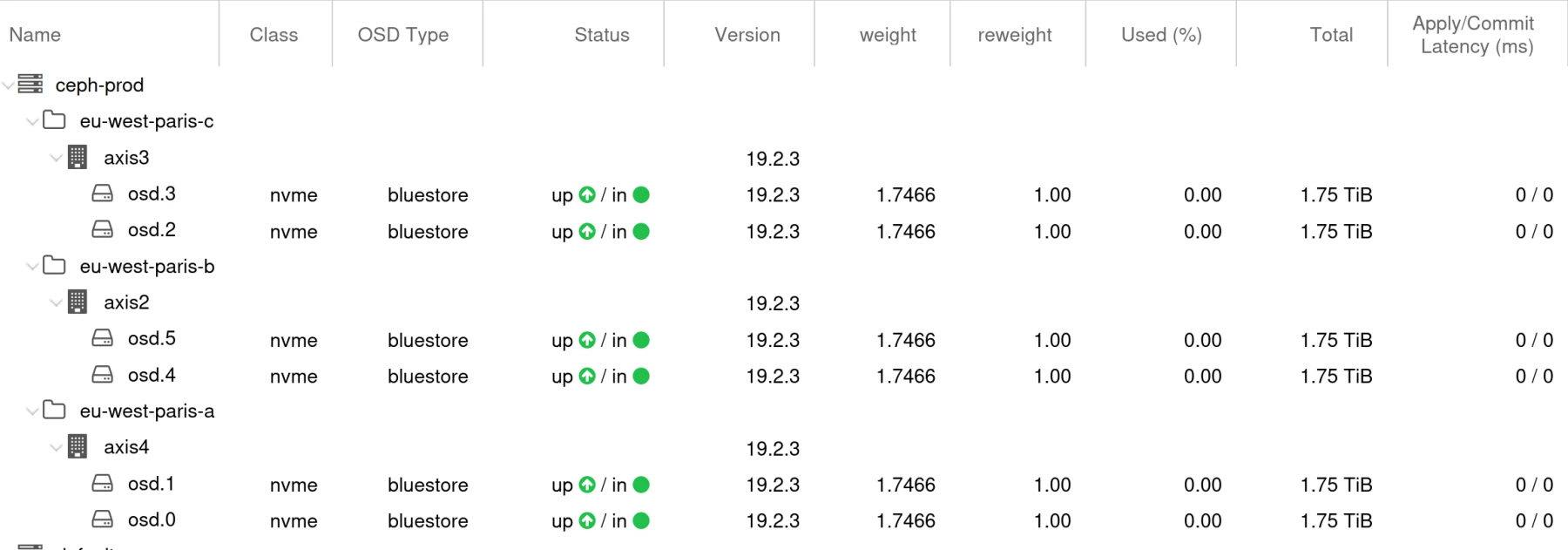
Chaque serveur héberge deux OSD NVMe, un moniteur (MON) et un manager (MGR).
Objectif : répliquer chaque bloc sur les trois sites tout en conservant des performances locales.
root ceph-prod
|--> datacenter paris-a → host serveur1 → osd.A1 / osd.A2 (NVMe)
|--> datacenter paris-b → host serveur2 → osd.B1 / osd.B2 (NVMe)
|--> datacenter paris-c → host serveur3 → osd.C1 / osd.C2 (NVMe)
Mise en place d’une CRUSH map adaptée
La CRUSH map (Controlled Replication Under Scalable Hashing) est le cœur de la logique de placement de Ceph. Elle décrit la hiérarchie de ton cluster — root → datacenter → host → osd — et les règles qui déterminent où et comment Ceph stocke les copies de chaque objet.
Dans une configuration multi-sites, c’est elle qui garantit qu’un objet ne sera jamais répliqué deux fois dans le même datacenter. Sans une CRUSH map bien pensée, une panne de site peut rendre ton cluster partiellement ou totalement indisponible.
L’objectif de cette section est donc de créer une arborescence hiérarchique correspondant à ta topologie physique (3 sites, 3 serveurs, 2 disques NVMe chacun) puis de définir une règle de réplication intelligente qui placera automatiquement les données à travers ces trois sites.
Créer un root dédié
Ce root servira de base pour isoler la hiérarchie de production du reste du cluster. Cela permet notamment de distinguer les règles de test, de production ou de classes de disques différentes.
ceph osd crush add-bucket ceph-prod root
Déclarer les sites
Chaque site (ou AZ) est représenté par un bucket de type datacenter.
On les rattache ensuite au root ceph-prod pour former la structure logique de plus haut niveau.
ceph osd crush add-bucket paris-a datacenter
ceph osd crush add-bucket paris-b datacenter
ceph osd crush add-bucket paris-c datacenter
ceph osd crush move paris-a root=ceph-prod
ceph osd crush move paris-b root=ceph-prod
ceph osd crush move paris-c root=ceph-prodAssocier les hôtes à leurs sites
Ensuite, on rattache chaque serveur physique (bucket host) au datacenter correspondant. Ce mapping garantit que Ceph connaît la position de chaque OSD dans la topologie.
ceph osd crush move serveur1 datacenter=paris-a
ceph osd crush move serveur2 datacenter=paris-b
ceph osd crush move serveur3 datacenter=paris-c
Créer la règle de réplication
Une fois la hiérarchie en place, on crée une règle CRUSH qui détermine comment Ceph choisit les OSD lors d’une écriture.
Ici, la commande suivante crée la règle nvme-by-site qui sélectionne 1 OSD par datacenter en utilisant uniquement la classe nvme :
ceph osd crush rule create-replicated nvme-by-site ceph-prod datacenter nvmeCette règle garantit une répartition optimale :
- un objet sera toujours répliqué sur trois sites distincts
- chacun utilisant un disque NVMe
Appliquer la règle aux pools
Enfin, on applique cette règle au pool principal (rbd dans notre exemple).
Cela assure que tous les blocs d’images stockés par Proxmox suivent les bonnes contraintes de réplication.
ceph osd pool create rbd 128 128 replicated
ceph osd pool set rbd size 3
ceph osd pool set rbd min_size 2
ceph osd pool set rbd crush_rule nvme-by-site
ceph osd pool application enable rbd rbdUne fois cette étape terminée, Ceph sait exactement comment distribuer et équilibrer les données à travers les trois sites. Tu obtiens ainsi un cluster où chaque réplique est isolée géographiquement, garantissant une vraie tolérance de panne inter-site sans compromis sur la performance.
Validation du placement
Vérifiez que Ceph place bien une réplique sur chaque site :
ceph osd map rbd testobjRésultat attendu : 3 OSD distincts, chacun dans un datacenter différent.
CephFS et intégration Proxmox
Une fois la partie stockage d’objets et blocs en place, il est temps d’ajouter un système de fichiers distribué : CephFS. C’est lui qui permet à tous les nœuds du cluster Proxmox d’accéder à un même espace partagé, utile pour héberger :
- les ISOs et templates de VM,
- les backups et snippets,
- et plus généralement tout contenu que tu veux rendre disponible sur l’ensemble des nœuds.
CephFS repose sur deux types de pools :
cephfs_data— pour les données réelles,
cephfs_metadata— pour les métadonnées du système de fichiers (inodes, répertoires, permissions…).
Les deux pools utilisent la règle
nvme-by-siteafin de garantir une répartition géographique identique à celle de tes volumes RBD.
Créer les pools CephFS
On crée les deux pools avec la réplication sur 3 sites et on applique la règle CRUSH personnalisée :
ceph osd pool create cephfs_data 128 128 replicated
ceph osd pool create cephfs_metadata 32 32 replicated
ceph osd pool set cephfs_data crush_rule nvme-by-site
ceph osd pool set cephfs_metadata crush_rule nvme-by-siteCréer le système de fichiers
Une fois les pools créés, on peut initialiser le système de fichiers CephFS lui-même. Cette commande lie les deux pools précédents et crée le FS distribué :
ceph fs new cephfs cephfs_metadata cephfs_dataTu peux ensuite vérifier la bonne création du FS avec :
ceph fs lsDémarrer et vérifier les daemons MDS
Les MDS (Metadata Servers) gèrent la structure du système de fichiers (arborescence, fichiers, répertoires). Sans MDS actif, CephFS ne pourra pas monter ni fonctionner correctement.
Sur un cluster Proxmox, on les déploie facilement depuis un nœud :
pveceph mds createEt on vérifie leur état :
ceph mds statActiver les applications sur les pools
Chaque pool doit être explicitement associé à son usage CephFS pour éviter les alertes “application not enabled” :
ceph osd pool application enable cephfs_data cephfs
ceph osd pool application enable cephfs_metadata cephfsIntégration dans Proxmox
C’est la partie la plus visible côté interface. Depuis l’interface Web Proxmox :
- Va dans Datacenter → Storage → Add → CephFS
- Indique :
- Monitors : les IPs ou FQDNs de tes moniteurs Ceph
- User :
admin - Mountpoint :
/mnt/pve/cephfs - Contenus : ISO, images, backups, snippets selon ton usage
💡 Une fois ajouté, le CephFS apparaît comme un stockage partagé dans ton cluster Proxmox. Toutes les machines virtuelles peuvent y accéder, et il devient possible de déplacer, sauvegarder ou restaurer des VMs entre nœuds sans transfert manuel.
Vérification finale
Pour t’assurer que tout fonctionne :
ceph -s
ceph fs status
df -h /mnt/pve/cephfsSi tout est en active+clean et que le point de montage CephFS affiche bien son espace total (~10 TiB dans cet exemple), ton stockage distribué est entièrement opérationnel.
Avec CephFS, tu obtiens un espace mutualisé cohérent sur l’ensemble de ton cluster Proxmox, tout en conservant la même logique de redondance que pour tes disques RBD. Résultat : zéro point de défaillance, fichiers centralisés et haute disponibilité de bout en bout.
Bonnes pratiques CephFS
Une fois CephFS déployé et intégré à Proxmox, voici quelques réglages et opérations recommandées pour maintenir des performances stables et garantir la fiabilité du stockage distribué.
1. Utiliser le montage kernel RBD (krbd)
Par défaut, Proxmox monte les volumes Ceph via le client utilisateur libRBD. Pour améliorer les performances et réduire la latence, il est conseillé d'activer le driver kernel RBD (krbd), qui permet au système de communiquer directement avec le noyau Linux sans passer par le processus utilisateur.
Dans ton interface Proxmox, édite le stockage Ceph concerné et ajoute l’option suivante :
krbd: 1Ou dans le fichier de configuration :
/etc/pve/storage.cfgExemple pour un stockage RBD :
rbd: ceph-rbd
pool cephfs_data
content images,rootdir
krbd 1
Ce réglage réduit la latence d’E/S, améliore les débits et libère une partie des ressources CPU utilisées par QEMU.
2. Gestion du cache MDS
Les serveurs de métadonnées (MDS) utilisent un cache mémoire pour accélérer l’accès aux fichiers et répertoires. Sur un cluster avec beaucoup de fichiers ou d’utilisateurs, ajuste la limite mémoire afin d’éviter les ralentissements :
ceph config set mds mds_cache_memory_limit 4GSurveille ensuite la consommation via :
ceph tell mds.* heap statsUn cache trop petit provoque une baisse de performance, tandis qu’un cache trop grand peut entraîner du swap ou des blocages système.
3. Snapshots CephFS
CephFS prend en charge les snapshots de répertoires, utiles pour les sauvegardes ponctuelles ou la restauration rapide d’un projet.
ceph fs subvolume snapshot create cephfs nom_volume nom_snapshotSuppression d’un snapshot :
ceph fs subvolume snapshot rm cephfs nom_volume nom_snapshotCes snapshots sont légers et peuvent être automatisés via un script ou un cron sur le cluster Proxmox.
4. Vérification et maintenance
Pour garantir l’intégrité du système de fichiers et détecter d’éventuelles incohérences, lance régulièrement un scrub CephFS :
ceph fs scrub start cephfsCeph exécute alors un contrôle de cohérence complet en tâche de fond. Sur une infrastructure stable, une vérification mensuelle est généralement suffisante.
5. Surveillance et état du cluster
Pour suivre en continu l’état de ton CephFS et des MDS :
ceph fs status
ceph df
ceph mds statCes commandes te permettent d’identifier rapidement les déséquilibres, erreurs de cache ou blocages.
6. Sous-volumes et quotas
Pour isoler différents environnements (projets, clients, workloads), tu peux créer des sous-volumes avec des quotas de taille :
ceph fs subvolume create cephfs projetA --size 500G
ceph fs subvolume create cephfs projetB --size 1TChaque sous-volume fonctionne comme un espace dédié, avec son propre quota et point de montage, limitant ainsi l'impact d’un usage excessif sur les autres.
En appliquant ces bonnes pratiques -- utilisation de krbd, gestion du cache MDS, snapshots, vérifications régulières et quotas -- tu garantis à ton cluster CephFS stabilité, performance et évolutivité.
CephFS devient alors un socle partagé robuste pour ton infrastructure Proxmox, capable de supporter un usage multi-site sans perte de performances.
Problèmes fréquents
- PGs unknown → mauvaise règle CRUSH →
ceph osd pool set <pool> crush_rule nvme-by-site - HEALTH_WARN pool(s) → app non activée →
ceph osd pool application enable <pool> cephfs - No MDS active → lancer
pveceph mds create - Réplicas mal répartis → mauvaise classe →
ceph osd crush set-device-class nvme osd.X
Conclusion
En repensant la logique de placement et la topologie de réplication, Ceph passe d’un simple stockage distribué à une véritable brique d’infrastructure haute disponibilité. L’intégration fine avec Proxmox, associée à une CRUSH map optimisée, permet de garantir à la fois performance et résilience entre plusieurs sites physiques.
Chez Greenhoster, cette approche multi-AZ n’est pas théorique : elle nous permet d’exploiter des clusters NVMe capables d’encaisser la perte d’un datacenter complet sans interruption de service.
La combinaison Proxmox + Ceph + CRUSH map personnalisée offre une base technique robuste, adaptable à tout type de projet cloud privé ou hébergé.
Au-delà de la technique, c’est une philosophie d’architecture : penser l’infrastructure non pas comme un ensemble de serveurs, mais comme un système distribué cohérent et auto-résilient. Ceph, bien configuré, devient un allié invisible qui assure que chaque bit de donnée reste disponible, où que l’on se trouve dans la topologie.
Dans un prochain article, nous aborderons les outils de supervision Ceph (Grafana, Prometheus, alerting) et les bonnes pratiques d’exploitation quotidienne pour surveiller la santé d’un cluster multi-site sans complexité inutile.
FAQ : CRUSH map Ceph et multi-AZ
Qu’est-ce qu’une CRUSH map dans Ceph ?
C’est la carte de placement des données (root → datacenter → host → OSD) qui définit comment Ceph distribue ses réplicas intelligemment.
Pourquoi créer un root personnalisé ?
Pour séparer la topologie multi-site du root global et appliquer des règles CRUSH dédiées.
Que fait la règle nvme-by-site ?
Elle place une réplique par datacenter sur les disques NVMe uniquement.
Différence entre size et min_size ?
size = copies totales, min_size = copies minimales requises pour rester opérationnel.
CephFS est-il obligatoire ?
Non, mais il est recommandé pour partager ISO, templates et backups.
Comment vérifier la répartition ?
ceph osd map rbd testobj → 3 OSD sur 3 sites différents.Que se passe-t-il si un site tombe ?
Ceph reste disponible avec min_size=2 et se reconstruit automatiquement au retour du site.
Peut-on mélanger plusieurs types de disques ?
Oui, mais mieux vaut définir une classe par type (nvme, ssd, hdd).
Comment sauvegarder la CRUSH map ?
ceph osd getcrushmap -o ceph-crushmap.bin && crushtool -d ceph-crushmap.bin -o ceph-crushmap.txt
Bonne procédure de maintenance OSD en multi-AZ ?
ceph osd out <id>- attendre migration
ceph -s - intervenir
ceph osd in <id>- laisser rebuilder.