Sommaire
- Le contexte : 6 nœuds, 3 AZ, 138 To brut
- Pourquoi quitter ZFS local
- Préparation : vider et wiper les pools ZFS
- La CRUSH map : la clé de la tolérance inter-AZ
- Migration des images ZFS vers RBD
- Thin provisioning : récupérer l'espace après migration
- Cas particulier : VMs Windows et driver VirtIO
- Limitation connue : krbd et discard sous Proxmox 9
- Points de vigilance en production
- Bilan et prochaines étapes
- Greenhoster déploie et opère votre cluster Proxmox Ceph
Migrer le stockage d'un cluster Proxmox de ZFS local vers Ceph distribué est une étape structurante. Elle conditionne la mobilité des VMs entre nœuds, la tolérance aux pannes, et la densité de stockage réelle disponible. Ce retour d'expérience couvre l'intégralité de la bascule sur 6 serveurs bare-metal OVHcloud à Paris, avec Proxmox VE 9 et Ceph 19 (Squid), du wipe ZFS jusqu'à la récupération du thin provisioning sur les images RBD.
Le contexte : 6 nœuds, 3 AZ, 138 To brut
L'infrastructure cible repose sur 6 serveurs HGR-HCI-i2 OVHcloud hébergés dans les datacenters parisiens d'OVH, répartis sur 3 zones de disponibilité distinctes. Chaque nœud embarque 6 NVMe Samsung 3,84 To et 512 Go de RAM.
En configuration ZFS initiale, chaque nœud gérait son propre pool local en miroir. La réplication entre nœuds reposait sur ZFS send/receive en mode asynchrone, avec une fenêtre de synchronisation de l'ordre de 10 minutes. La bascule HA Proxmox était donc limitée aux nœuds possédant une copie à jour du disque concerné : impossible de redémarrer une VM sur un hôte qui n'en avait pas reçu la réplication.
Ce modèle fonctionne correctement sur un petit nombre de machines qui tolère une perte de 5-10 min de données. Dès que le parc grandit, la gestion des réplications ZFS sur chaque noeud et le ciblage des serveurs HA éligibles devient une usine à gaz. Chaque ajout de nœud multiplie les règles à maintenir, et la moindre rupture de réplication crée des angles morts invisibles dans la configuration HA.
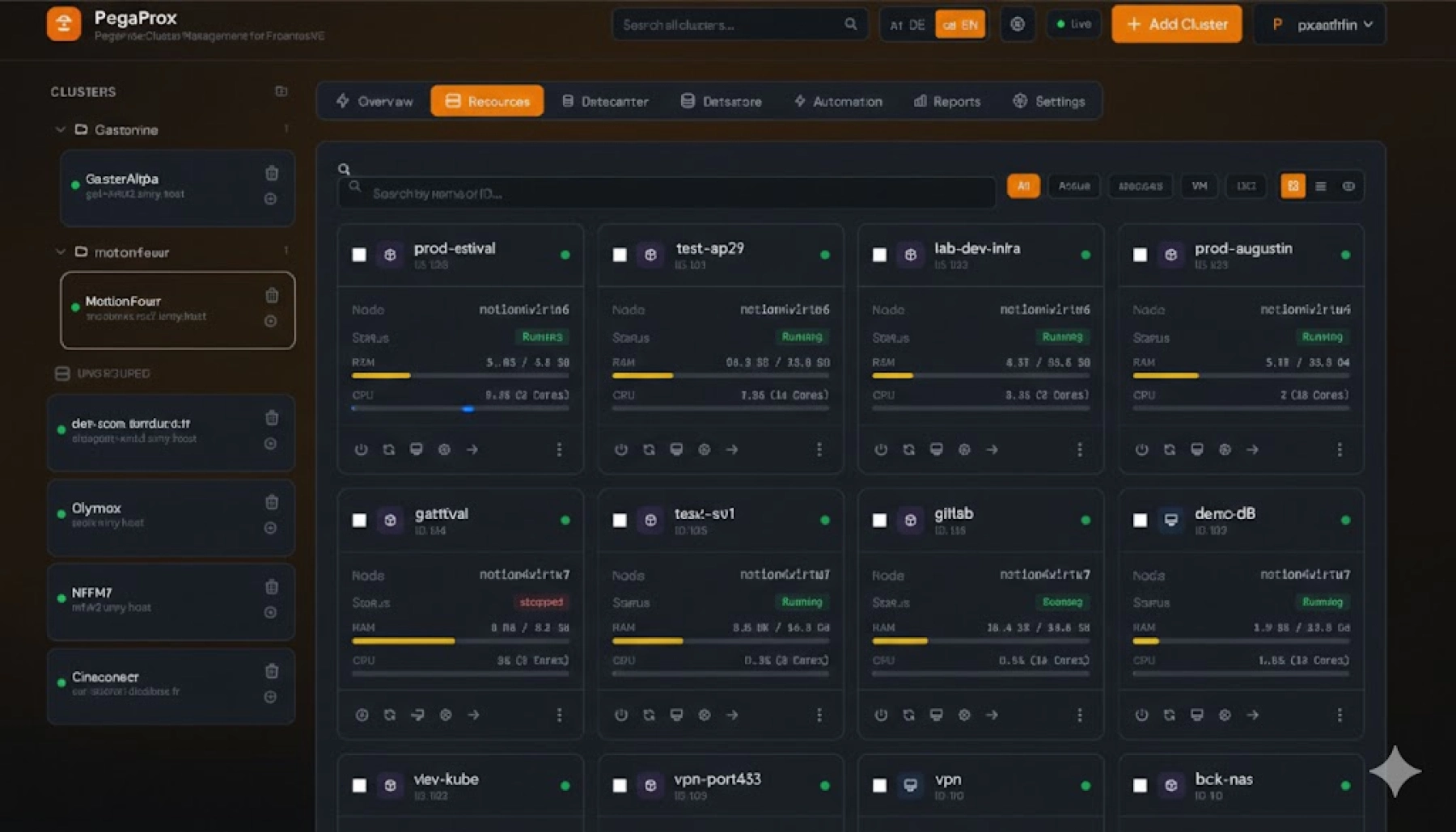
Avec Ceph, les 36 NVMe deviennent 36 OSDs dans un pool unique répliqué 3 fois entre les 3 AZ. La capacité utilisable nette atteint environ 46 To, et chaque VM peut démarrer sur n'importe quel nœud sans déplacement de données ni règle de ciblage à maintenir.
- 36 OSDs NVMe répartis sur 6 hôtes dans 3 datacenters
- 138 To brut, environ 46 To utilisables avec réplication x3
- Survie à la panne complète d'une AZ (2 nœuds simultanément)
- Migration VM instantanée entre nœuds sans copie réseau
Pourquoi quitter ZFS local
ZFS est un système de fichiers robuste et éprouvé. Sur un nœud unique, ses fonctionnalités de compression, de snapshot et de vérification d'intégrité sont difficiles à battre. Le problème est architectural : ZFS est conçu pour un hôte, pas pour un cluster temps réel.
Dans un cluster Proxmox multi-nœuds, les pools ZFS locaux créent des îlots de stockage. La haute disponibilité Proxmox (HA) peut redémarrer une VM sur un autre nœud en cas de panne, mais uniquement si le disque de cette VM est synchrnosié vers ce nœud. Avec ZFS local, la réplication est asynchrone et en cas d'incident risque de générer une perte de données conséquente. Résultat : la HA Proxmox est limité et difficile à maintenir sans stockage partagé.
Ceph résout ce problème structurellement. Le pool RBD est accessible depuis tous les nœuds simultanément. Une VM peut démarrer, migrer à chaud (live migration) ou être relancée après panne depuis n'importe quel membre du cluster, sans aucune copie de données.
Préparation : vider et wiper les pools ZFS
Avant d'intégrer les disques comme OSDs Ceph, il faut s'assurer qu'aucune VM ou conteneur n'utilise encore le stockage ZFS local, puis détruire les pools et nettoyer les disques.
Sur chaque nœud à migrer, vérifier que le pool est bien vide :
zfs list -r data-zfs
grep -r "data-zfs" /etc/pve/qemu-server/*.conf /etc/pve/lxc/*.confUne fois les VMs évacuées vers les autres nœuds du cluster, détruire le pool et wiper les disques :
zpool destroy data-zfs
for dev in nvme0n1 nvme1n1 nvme4n1 nvme5n1 nvme6n1 nvme7n1; do
wipefs -a /dev/$dev
sgdisk --zap-all /dev/$dev
doneLes disques sont ensuite prêts à être ajoutés comme OSDs depuis l'interface Proxmox ou via ceph-volume.
La CRUSH map : la clé de la tolérance inter-AZ
Ceph distribue les données selon des règles définies dans une CRUSH map. Par défaut, Proxmox configure une règle de réplication au niveau hôte. Pour une tolérance inter-AZ réelle, il faut une règle qui force le placement des 3 réplicas sur 3 datacenters distincts.
Notre article dédié à Ceph sur Proxmox multi-AZ détaille la logique de la CRUSH map et les commandes de configuration. En résumé, la hiérarchie doit refléter la topologie physique :
ceph osd tree
# Vérifier que chaque OSD est bien rattaché au bon host,
# lui-même rattaché au bon datacenter dans la hiérarchie CRUSHUn point de vigilance : la CRUSH rule doit correspondre exactement au nombre de nœuds disponibles. Une règle exigeant 3 hôtes distincts avec seulement 2 hôtes actifs laisse des PGs en état inactif. Vérifier l'état du cluster après chaque ajout ou retrait d'OSD :
ceph status
ceph health detail
Migration des images ZFS vers RBD
Proxmox permet de déplacer les disques d'une VM entre storages directement depuis l'interface, via le bouton "Move Disk" dans l'onglet Hardware de la VM. L'opération est également réalisable en CLI :
# Déplacer un disque ide vers le pool Ceph et supprimer l'original
qm move-disk 134 ide0 shared --delete 1Proxmox copie l'image raw vers le pool RBD, met à jour la configuration de la VM et supprime l'ancienne image ZFS. Les disques de données peuvent être déplacés à chaud. Le disque de boot nécessite un arrêt préalable de la VM.
Une fois la migration effectuée, vérifier que le disque est bien référencé sur le bon storage dans la configuration :
grep ide /etc/pve/qemu-server/134.confLe disque est alors sur Ceph mais toujours en bus ide. Le changement vers scsi avec discard=on est une étape séparée, décrite dans la section suivante.
Thin provisioning : récupérer l'espace après migration
C'est le piège le plus courant après une migration ZFS vers Ceph. qemu-img convert écrit l'intégralité de l'image, y compris les blocs vides (zéros). Résultat : une VM Windows dont le disque de 80 Go n'utilise réellement que 30 Go affichera 80 Go utilisés dans Ceph (rbd du).
Deux approches permettent de récupérer cet espace :
À froid (VM éteinte) : rbd sparsify parcourt tous les objets RBD et supprime ceux qui ne contiennent que des zéros. C'est la méthode la plus directe et la plus efficace après une migration.
# VM éteinte obligatoire
qm shutdown 134
rbd sparsify shared/vm-134-disk-0
rbd sparsify shared/vm-134-disk-1
rbd du shared/vm-134-disk-0
qm start 134À chaud (VM running) : via le guest agent Proxmox et le discard SCSI. Cette méthode nécessite que le disque soit en mode SCSI avec discard=on et que le driver VirtIO SCSI soit installé dans la VM. Elle maintient le thin provisioning dans le temps sans intervention manuelle.
# Vérifier la configuration du disque
grep scsi /etc/pve/qemu-server/134.conf
# Doit contenir : discard=on
# Lancer le fstrim depuis l'hôte
qm guest cmd 134 fstrim
# Vérifier le résultat dans Ceph
rbd du shared/vm-134-disk-0
Cas particulier : VMs Windows et driver VirtIO
Les VMs Windows installées avec des disques IDE ne peuvent pas bénéficier du discard. La migration vers des disques SCSI VirtIO est nécessaire, mais elle comporte un risque majeur : Windows ne charge pas le driver VirtIO SCSI par défaut. Retirer le disque IDE et le rattacher en SCSI sans driver préalable provoque un BSOD INACCESSIBLE_BOOT_DEVICE au démarrage.
La procédure sûre consiste à installer le driver à chaud, sans arrêter la VM. On ajoute un disque SCSI temporaire de petite taille, Windows détecte le nouveau contrôleur et installe le driver Red Hat VirtIO SCSI. Une fois le driver confirmé dans le Gestionnaire de périphériques, on peut arrêter la VM et migrer les disques de boot de IDE vers SCSI en toute sécurité.
# Ajouter un disque temporaire pour forcer l'installation du driver
qm set 160 --scsi0 shared:1,format=raw
# Vérifier dans Windows que "Red Hat VirtIO SCSI controller" est présent
# Puis arrêter et migrer les disques
qm shutdown 160
qm set 160 --scsi1 shared:vm-160-disk-0,cache=none,discard=on,size=80G
qm set 160 --boot order=scsi1
qm set 160 --delete ide0
qm start 160
Limitation connue : krbd et discard sous Proxmox 9
Proxmox utilise le driver krbd (kernel RBD) pour mapper les images Ceph comme des block devices Linux. Ce mode offre de meilleures performances en I/O direct, mais présente une limitation : Proxmox ne passe pas l'option discard lors du rbd map. Les commandes UNMAP envoyées par la VM via QEMU (discard=on, detect-zeroes=unmap) ne sont donc pas propagées jusqu'aux OSDs Ceph.
En pratique, pour les images issues de migration, rbd sparsify à froid reste la méthode la plus fiable pour récupérer l'espace. Pour les nouvelles VMs créées directement sur Ceph, le thin provisioning fonctionne nativement car les blocs non écrits ne sont jamais alloués.
Points de vigilance en production
Quelques apprentissages pratiques issus de cette migration en conditions réelles :
- selfmanaged_snaps bloque pgp_num : tant que des watchers RBD actifs (VMs running) maintiennent le flag selfmanaged_snaps, les modifications de pgp_num sont bloquées. Le rééquilibrage des PGs après ajout d'OSDs ne se termine pas. Il faut attendre une fenêtre de maintenance ou migrer les VMs hors cluster pour libérer les watchers.
- rbd sparsify échoue sur VM running : l'erreur lost exclusive lock / Read-only file system est normale. L'image est verrouillée par QEMU. Le sparsify ne fonctionne qu'à froid.
- Messenger krbd peut se corrompre : des erreurs -108 (ESHUTDOWN) sur les devices krbd indiquent une connexion Ceph cassée au niveau kernel. La seule résolution propre est un redémarrage du nœud concerné. Prévoir une procédure d'évacuation rapide des VMs avant reboot.
- proxmox-boot-tool obligatoire : lors de la réinstallation d'un nœud après incident, ne jamais utiliser grub-install directement. Proxmox gère le boot EFI via proxmox-boot-tool et attend shimx64.efi aux côtés de grubx64.efi.
Bilan et prochaines étapes
Après migration complète, le cluster présente une utilisation réelle du stockage Ceph réduite de 30 à 60% par rapport à l'affichage initial post-migration, selon le taux de remplissage des disques Windows. La mobilité des VMs entre nœuds est immédiate et la haute disponibilité Proxmox est opérationnelle sur l'ensemble du parc.
Les étapes suivantes incluent l'activation du discard natif sur toutes les VMs Windows via la migration IDE vers SCSI, la mise en place d'un fstrim.timer hebdomadaire via le guest agent, et la finalisation du rééquilibrage des PGs après intégration des derniers nœuds dans le pool Ceph.
Pour estimer la capacité utilisable de votre propre cluster selon votre topologie et votre facteur de réplication, le calculateur Ceph de CaptainAdmin est un outil pratique et rapide.
Greenhoster déploie et opère votre cluster Proxmox Ceph
Greenhoster conçoit, déploie et opère des infrastructures Proxmox sur des serveurs dédiés français, éthiques et écologiques. Nous intervenons sur l'ensemble de la chaîne : architecture Ceph multi-AZ, configuration CRUSH map, migration ZFS vers RBD, optimisation thin provisioning, et accompagnement des équipes techniques tout au long du projet.
Contactez-nous pour étudier votre projet d'infrastructure Proxmox.